4.7. Staging Unit Output Data¶
Upon completion, CUs have often creates some amount of data. We have seen in
Obtaining Unit Details how we can inspect the CU’s stdout string – but
that will not be useful beyond the most trivial workloads. This section
introduces how created data can be staged back to the RP application, and/or
staged to 3rd party storage.
Output staging is in principle specified just like the input staging discussed in the ref:previous <chapter_user_guide_05> section:
source: what data files need to be staged from the context of the finished CU;target: where should the data be staged to;action: how should data be staged.
In this example we actually use the long form, and specify the output file name to be changed to a unique name during staging:
for i in range(0, n):
cud.executable = '/bin/cp'
cud.arguments = ['-v', 'input.dat', 'output.dat']
cud.input_staging = ['input.dat']
cud.output_staging = {'source': 'output.dat',
'target': 'output_%03d.dat' % i,
'action': rp.TRANSFER}
06_unit_output_data.py
contains an example application which uses the above code block. It otherwise
does not significantly differ from our previous example.
4.7.1. Running the Example¶
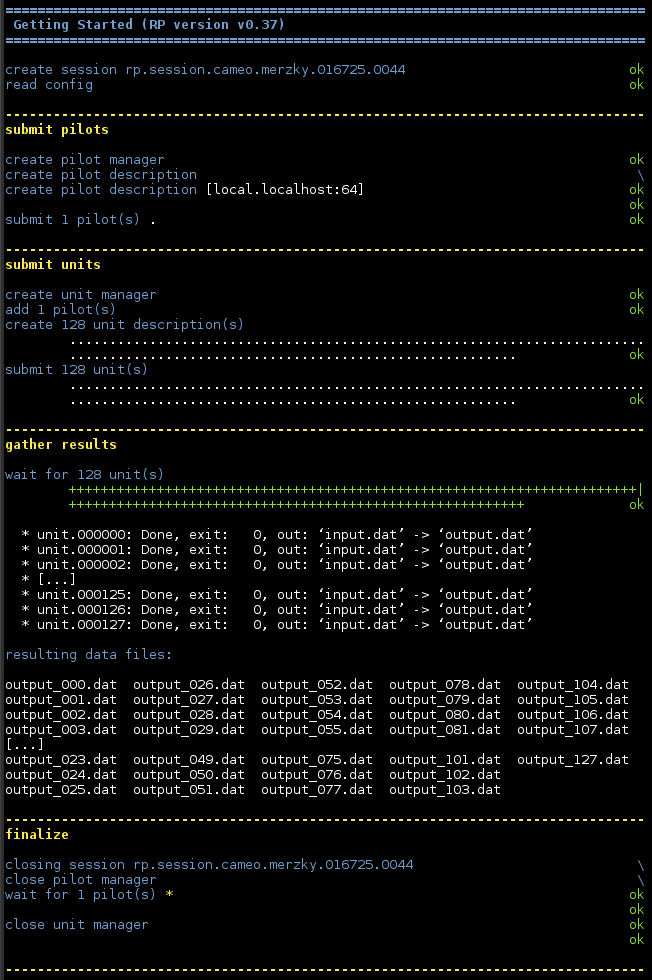
The result of this example’s execution shows that the output files have been renamed during the output-staging phase:
4.7.2. What’s Next?¶
As we are now comfortable with input and output staging, we will next look into an optimization which is important for a large set of use cases: the sharing of input data between multiple compute units.